
La maquinaria de síntesis de proteínas
Además de la plantilla de ARNm, muchas otras moléculas contribuyen al proceso de traducción. La composición de cada componente puede variar según la especie; por ejemplo, los ribosomas pueden consistir en diferentes números de ARN ribosomales (ARNr) y polipéptidos dependiendo del organismo. Sin embargo, las estructuras y funciones generales de la maquinaria de síntesis de proteínas son comparables de bacterias a células humanas. La traducción requiere la entrada de una plantilla de ARNm, ribosomas, ARNt y diversos factores enzimáticos.
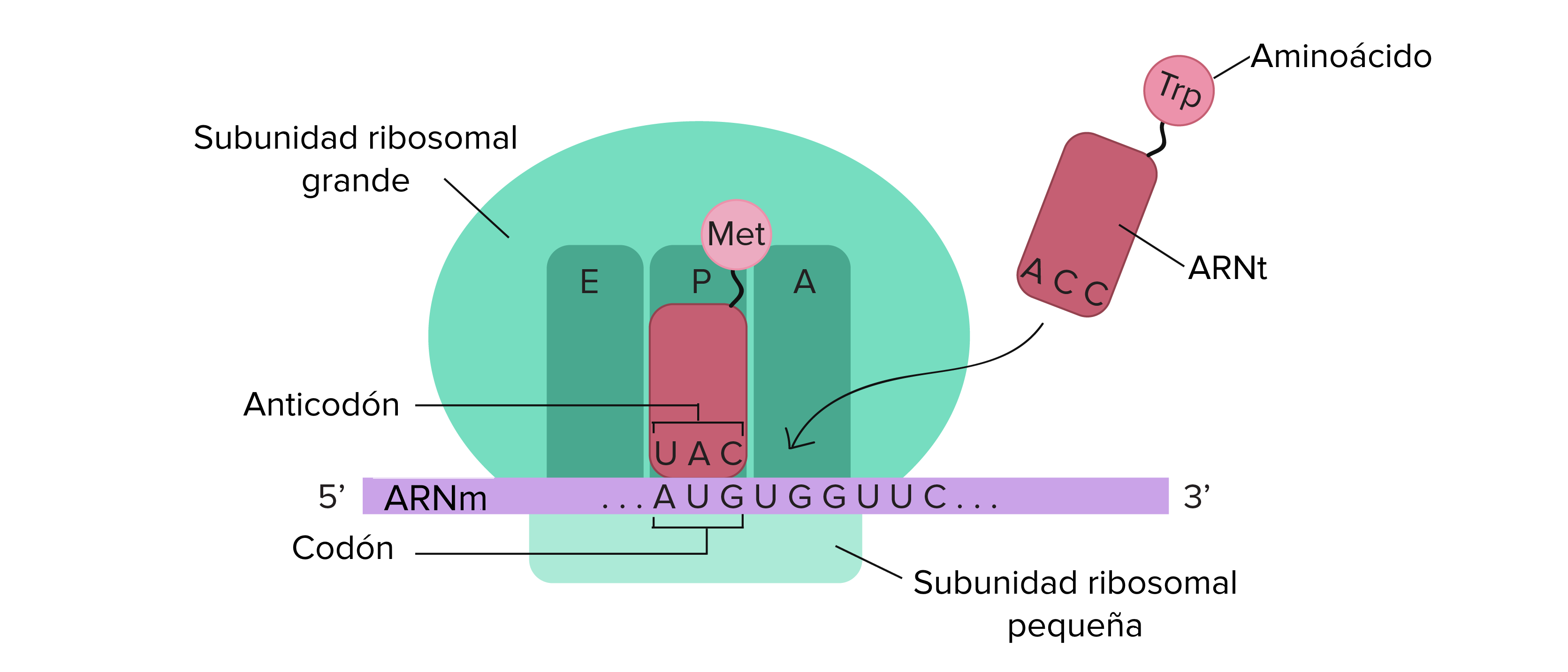 |
| La maquinaria de síntesis proteica incluye las subunidades grandes y pequeñas del ribosoma, ARNm y ARNt. |
En E. coli, hay 200,000 ribosomas presentes en cada célula en un momento dado. Un ribosoma es una macromolécula compleja compuesta de rRNAs estructurales y catalíticos, y muchos polipéptidos distintos. En eucariotas, el nucleolo está completamente especializado para la síntesis y ensamblaje de ARNr.
Los ribosomas se encuentran en el citoplasma en los procariotas y en el citoplasma y el retículo endoplásmico de los eucariotas. Los ribosomas están formados por una subunidad grande y una pequeña que se unen para la traducción. La subunidad pequeña es responsable de la unión de la plantilla de ARNm, mientras que la subunidad grande se une secuencialmente a los ARNt, un tipo de molécula de ARN que lleva los aminoácidos a la cadena de crecimiento del polipéptido. Cada molécula de ARNm es traducida simultáneamente por muchos ribosomas, todos sintetizando proteínas en la misma dirección.
Dependiendo de la especie, existen 40 a 60 tipos de ARNt en el citoplasma. Sirviendo como adaptadores, los ARNt específicos se unen a secuencias en la plantilla de ARNm y agregan el aminoácido correspondiente a la cadena de polipéptidos. Por lo tanto, los ARNt son las moléculas que realmente "traducen" el lenguaje del ARN al lenguaje de las proteínas. Para que cada tRNA funcione, debe tener su aminoácido específico unido a él. En el proceso de "carga" de tRNA, cada molécula de tRNA se une a su aminoácido correcto.
El código genético
Para resumir lo que sabemos hasta este punto, el proceso celular de transcripción genera ARN mensajero (ARNm), una copia molecular móvil de uno o más genes con un alfabeto de A, C, G y uracilo (U). La traducción de la plantilla de ARNm convierte la información genética basada en nucleótidos en un producto proteico. Las secuencias de proteínas consisten en 20 aminoácidos que ocurren comúnmente; por lo tanto, se puede decir que el alfabeto de proteínas consta de 20 letras. Cada aminoácido está definido por una secuencia de tres nucleótidos llamada codón triplete. La relación entre un codón de nucleótidos y su correspondiente aminoácido se denomina código genético.
Dados los diferentes números de "letras" en el ARNm y los "alfabetos" de proteínas, las combinaciones de nucleótidos correspondieron a aminoácidos individuales. El uso de un código de tres nucleótidos significa que hay un total de 64 (4 × 4 × 4) combinaciones posibles; por lo tanto, un aminoácido dado está codificado por más de un triplete de nucleótidos.
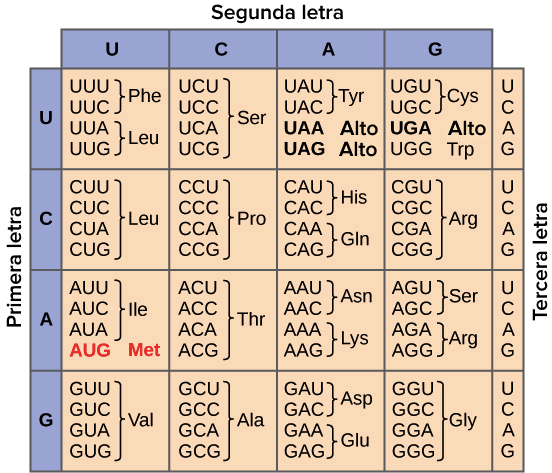 |
| Esta figura muestra el código genético para traducir cada triplete de nucleótidos, o codón, en ARNm en un aminoácido o una señal de terminación en una proteína naciente. |
Tres de los 64 codones terminan la síntesis de proteínas y liberan el polipéptido de la maquinaria de traducción. Estos trillizos se llaman codones de parada. Otro codón, AUG, también tiene una función especial. Además de especificar el aminoácido metionina, también sirve como codón de inicio para iniciar la traducción. El marco de lectura para la traducción lo establece el codón de inicio AUG cerca del extremo 5 'del ARNm. El código genético es universal. Con algunas excepciones, prácticamente todas las especies usan el mismo código genético para la síntesis de proteínas, lo cual es una evidencia poderosa de que toda la vida en la Tierra comparte un origen común.
El mecanismo de síntesis de proteínas
Al igual que con la síntesis de ARNm, la síntesis de proteínas se puede dividir en tres fases: iniciación, alargamiento y terminación. El proceso de traducción es similar en procariotas y eucariotas. Aquí exploraremos cómo ocurre la traducción en E. coli, un procariota representativo, y especificaremos las diferencias entre la traducción procariota y eucariota.
La síntesis de proteínas comienza con la formación de un complejo de iniciación. En E. coli, este complejo involucra la pequeña subunidad ribosómica, la plantilla de ARNm, tres factores de iniciación y un ARNt iniciador especial. El ARNt iniciador interactúa con el codón de inicio AUG y se une a una forma especial del aminoácido metionina que generalmente se elimina del polipéptido después de que se completa la traducción.
En procariotas y eucariotas, los principios básicos del alargamiento de polipéptidos son los mismos, por lo que revisaremos el alargamiento desde la perspectiva de E. coli. La gran subunidad ribosómica de E. coli consta de tres compartimentos: el sitio A se une a los tRNA cargados entrantes (tRNA con sus aminoácidos específicos unidos). El sitio P se une a los ARNt cargados que llevan aminoácidos que se han formado enlaces con la cadena de polipéptidos en crecimiento pero que aún no se han disociado de su ARNt correspondiente. El sitio E libera tRNAs disociados para que puedan recargarse con aminoácidos libres. El ribosoma cambia un codón a la vez, catalizando cada proceso que ocurre en los tres sitios. Con cada paso, un ARNt cargado entra en el complejo, el polipéptido se convierte en un aminoácido más y sale un ARNt sin carga. La energía para cada enlace entre aminoácidos se deriva de GTP, una molécula similar al ATP. Sorprendentemente, el aparato de traducción de E. coli tarda solo 0,05 segundos en agregar cada aminoácido, lo que significa que un polipéptido de 200 aminoácidos podría traducirse en solo 10 segundos.
 |
| La traducción comienza cuando un anticodón de ARNt reconoce un codón en el ARNm. La subunidad ribosómica grande se une a la subunidad pequeña, y se recluta un segundo ARNt. A medida que el ARNm se mueve con relación al ribosoma, se forma la cadena polipeptídica. La entrada de un factor de liberación en el sitio A finaliza la traducción y los componentes se disocian. |
¿Te sirvió el contenido del tema? ¿tienes alguna duda o sugerencia?
Puedes escribir un comentario en la parte de abajo y nosotros con gusto te responderemos. Esperemos que tengas un lindo día. ¡Mucho éxito en tus estudios!
Puedes escribir un comentario en la parte de abajo y nosotros con gusto te responderemos. Esperemos que tengas un lindo día. ¡Mucho éxito en tus estudios!